
مقدمهای بر Apache Airflow و راهنمای شروع به کار آن

آپاچی ایرفلو (Apache Airflow) یکی از ابزارهای کارآمد برای برنامهریزی و زمانبندی و نظارت بر دادههاست. این ابزار کاربردهای گوناگونی دارد؛ اما ویژگیها و ابزارهای تعبیهشده در آن برای تحلیلگران داده مناسبتر است. آپاچی ایرفلو بهصورت متنباز طراحی شده است و رکورد ۹میلیون بار دانلود در ماه را دارد. جامعه بزرگ کاربران این برنامه یکی دیگر از دلایل واضح برای اعتماد به آن است. موضوع مقاله حاضر مقدمهای بر Apache Airflow و راهنمای شروع به کار آن است. برای آشنایی بیشتر با این ابزار کاربردی، با ما همراه باشید.
تاریخچهای مختصر درباره Apache Airflow
قبل از هرچیز باید بدانید که برای استفاده بهتر از Apache Airflow، لازم است با مفاهیم اولیه برنامهنویسی با زبان پایتون (Python) آشنا باشید. درک مفاهیم کلی مانند پکیجها و توابع این زبان برنامهنویسی برای درک مفاهیم این آموزش کافی است. آپاچی ایرفلو ابتدا کارش را بهعنوان پروژهای متنباز در Airbnb آغاز کرد. در سال ۲۰۱۵، این شرکت بهسرعت در حال رشد بود و هرروز با حجم بیشتری از دادههای داخلی روبهرو میشد؛ اما برای تبدیلشدن به یکی از قطبهای تحلیل داده، باید نیروهای کاری خود اعم از تحلیلگران و متخصصان داده را افزایش میداد.
در آن برهه زمانی، ماکسیم بوشمین (Maxime Beauchemin) توانست Airflow را بهصورت متنباز طراحی کند تا با استفاده از آن، پایپلاینهای داده را بهصورت دستهای بنویسند و آن را تکرار و بر آن نظارت کنند. از آن زمان تاکنون، شاهد پیشرفتهای زیادی در آپاچی ایرفلو بودهایم. در آوریل۲۰۱۶، این پروژه به انکوباتور رسمی Apache Foundation پیوست و در سال ۲۰۱۹، بهعنوان پروژهای پیشرفته دردسترس قرار گرفت. از آگوست۲۰۲۲ نیز، این ابزار بیشتر از ۲,۰۰۰ مشارکتکننده و ۱۶,۹۰۰ کامیت و ۲۶,۹۰۰ ستاره در GitHub کسب کرده است که این اعداد و ارقام از محبوبیت چشمگیر آن در بین مهندسان داده حکایت میکند.

چرا باید از Airflow استفاده کنیم؟
دلایل زیادی وجود دارد که استفاده از Apache Airflow را توجیهپذیر میکند. برخی از این دلایل عبارتاند از:
۱. پایپلاین داده پویا
در ایرفلو، پایپلاینها بهعنوان کد پایتون تعریف میشوند؛ بنابراین، هر کاری که در پایتون میتوانید انجام دهید، در ایرفلو نیز انجامدادنی است.
۲. استفاده از فرایندهای CI/CD
CI/CD روشی است که با استفاده از آن، ارائه نرمافزار تولیدشده به کاربران با استفاده از اتوماسیون در فرایندهای توسعه نرمافزار تسریع میشود. به این فرایند ادغام یا تحویل مداوم گفته میشود. با استفاده از منطق گردش کاری که براساس پایتون میتوان به آن دست یافت، پیادهسازی فرایندهای CI/CD روی پایپلاینهای داده امکانپذیر است.
۳. ابزارهای آگنوستیک
یکی دیگر از ویژگیهای ایرفلو آن است که این ابزار میتواند به هر ابزار دیگری متصل شود که امکان اتصال ازطریق API را فراهم میکند.
۴. توسعهپذیری کمنظیر
برای بسیاری از ابزارهای متداول در علم مهندسی داده، پکیجهایی بهصورت Provider در ایرفلو وجود دارد که معمولاً گسترش مییابند و بهروز میشوند.
۵. مقیاسپذیری درخورتوجه
باتوجهبه قدرت محاسباتی چشمگیر آپاچی ایرفلو، میتوانید هر تعداد از فرایندهای مدنظرتان را بدون توجه به اینکه پایپلاینهای شما چقدر پیچیده باشند، با یکدیگر هماهنگ کنید.
۶. رابط کاربری ساده
ایرفلو UI کاملاً کاربردی دارد که بهکمک آن خواهید توانست به نمایی کلی از پایپلاینهای داده دسترسی داشته باشید.
کاربرد Airflow
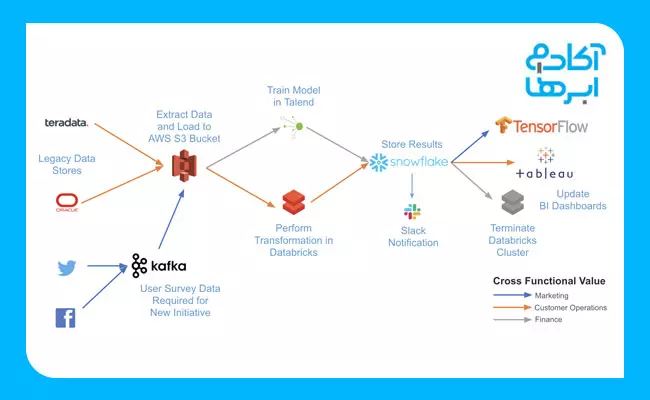
از ایرفلو تقریباً میتوان برای هر دسته از پایپلاینهای داده بهره برد. این ابزار کاربردهای زیادی دارد؛ بهخصوص برای سازماندهی مشاغل مختلف که وابستگیهای پیچیدهای در سیستمهای خارجی دارند. بهعنوان نمونه، در تصویر زیر میتوانید نمونهای از وابستگیهای پیچیدهای را ببینید که Airflow بهراحتی میتواند در ساماندهی این بخشها به شما کمک کند. شما با پلتفرمی واحد میتوانید پایپلاینهای خود را بهصورت کد بنویسید و از بسیاری از Providerهای قرارگرفته در ایرفلو بهره ببرید تا تمامی این پایپلاینها را با یکدیگر هماهنگ و بر آنها نظارت کنید.
چطور آپاچی ایرفلو را نصب کنیم؟
حالا بهتر است یاد بگیرید که چطور آپاچی ایرفلو را روی سیستم خود نصب کنید. برای این منظور، ابتدا باید pip را نصب کنید؛ بنابراین، اگر قبلاً آن را نصب کردهاید، به مرحله بعدی بروید؛ وگرنه دستور زیر را در ترمینال لینوکس وارد کنید:
sudo apt-get install python3-pip
در مرحله بعد، باید فضایی برای ذخیره Apache Airflow روی سیستمتان در نظر بگیرید. بهصورت پیشفرض این محل airflow/~ است؛ اما بسته به نیازتان میتوانید این محل را تغییر دهید:
export AIRFLOW_HOME=~/airflow
حالا با استفاده از pip، ایرفلو را با کدنویسی بهصورت زیر نصب کنید:
pip3 install apache-airflow
نکته دیگر این است که ایرفلو برای اجرای گردش کاری و ذخیره آن به پایگاهداده نیاز دارد. برای مقداردهی اولیه دیتابیس، بهصورت زیر کدنویسی کنید:
airflow initdb
همانطورکه قبلاً نیز گفتیم، آپاچی ایرفلو UI کاملاً کاربردی دارد. برای راهاندازی وبسرور دستور زیر را در ترمینال لینوکس اجرا کنید. فراموش نکنید که پورت پیشفرض برای این منظور 8080 است. اگر از این پورت برای کار دیگری استفاده کردهاید، میتوانید آن را تغییر دهید:
airflow webserver -p 8080
حالا باید برنامه زمانبندی ایرفلو را با استفاده از کدهای زیر در ترمینالی دیگر شروع کنید:
airflow scheduler
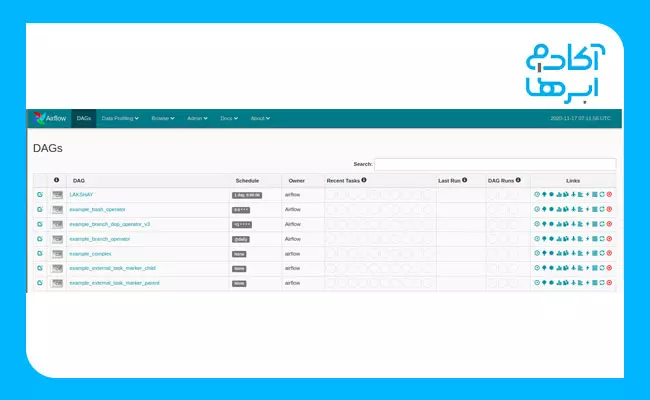
در گام بعدی، باید پوشه جدید با نام dags در دایرکتوری airflow ایجاد کنید. در این پوشه، میتوانید گردش کار یا DAGهای خود را تعریف کنید. مرورگر وب خود را باز و این آدرس را در آن وارد کنید:
درادامه، با تصویری مشابه با تصویر زیر روبهرو میشوید:
اجزای آپاچی ایرفلو
کامپوننتها یا اجزای آپاچی ایرفلو عبارتاند از:
DAG: مخفف عبارت Directed Acyclic Graph بهمعنای گراف غیرچرخشی جهتدار است. این کامپوننت حاوی تمام تسکهای سازماندهیشدهای است که میخواهید اجرا کنید. همچنین، این کامپوننت رابطه بین وظایف مختلف را نشان میدهد و در اسکریپت پایتون تعریف شده است.
Web Server: وبسرور همان رابط کاربری ایرفلوست که روی Flask ساخته شده است. وبسرور به شما امکان خواهد داد که روی وضعیت DAGها نظارت و آنها را فعال کنید.
Metadata Database: ایرفلو وضعیت تمامی Taskها را در یک پایگاهداده ذخیره میکند و تمامی عملیات خواندن یا نوشتن گردش کار را با استفاده از Metadata Database انجام میدهد.
Scheduler: همانطورکه از نام آن پیداست، این کامپوننت وظیفه دارد اجرای DAGها را زمانبندی و وضعیت کار را در پایگاهداده بازیابی و بهروز کند.
بررسی سریع رابط کاربری در آپاچی ایرفلو
تا اینجا اطلاعاتی کلی درباره آپاچی ایرفلو بهدست آوردید و با نحوه نصب آن نیز آشنا شدید. درادامه، برخی از اجزای مهم در رابط کاربری آن را مرور خواهیم کرد:
1. DAG View
در تصویر زیر، نمای پیشفرض رابط کاربری نشان داده شده است. آنچه در این قسمت مشاهده میکنید، شامل تمامی DAGGهای موجود در سیستم شماست. علاوهبراین، اطلاعات دیگری مانند اینکه DAGG خاص چند بار بهصورت موفقیتآمیز و چند بار با شکست اجرا شده است و آخرین زمان اجرا و برخی از پیوندهای مفید دیگر، در این قسمت به شما ارائه خواهد شد.
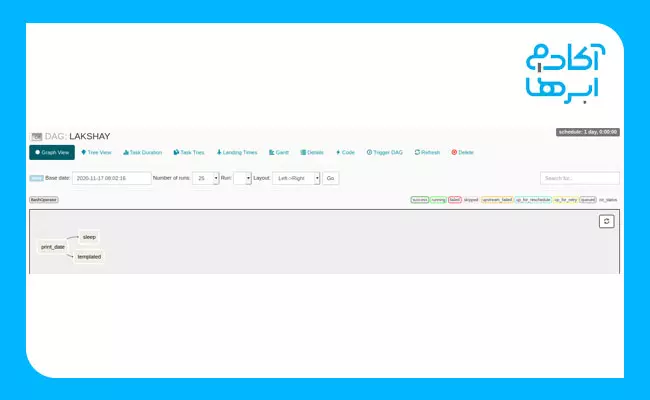
2. Graph View
در نمای GRAPH، میتوانید هر مرحله از گردش کار خود را با وابستگیهای درنظرگرفتهشده برای آن و وضعیت فعلیاش مشاهده کنید. هریک از این وضعیتها را میتوان با کدهای رنگی متفاوتی دستهبندی کرد. درادامه، فهرستی از این رنگها را مشاهده میکنید:

در تصویر زیر نیز، نمایی از GRAPH را مشاهده میکنید:
3. Tree View
نمای درختی (Tree) نیز نمایانگر DAG است. کاربرد این نما وقتی بیشتر مشخص میشود که اجرای پایپلاینهای شما بیشتر از حد معمول بهطول انجامیده است. در این مواقع، میتوانید بررسی کنید که کدامیک از اجزا زمان زیادی را ازآنِ خود کرده است و پسازآن خواهید توانست مشکل ایجادشده را برطرف کنید. در تصویر زیر، نمونه این نما نشان داده شده است:
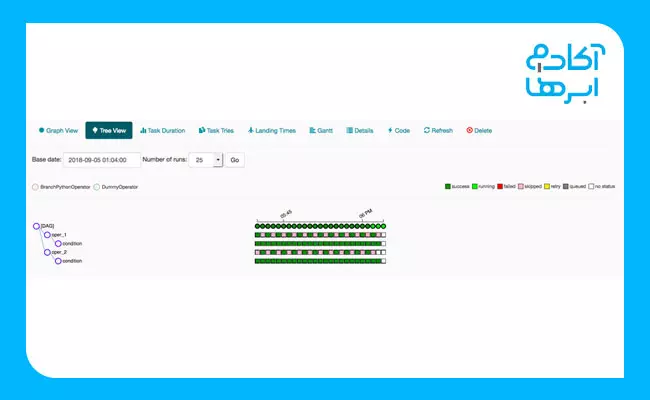
4. Task Duration
در این نما، میتوانید مدتزمان هر تسک را در بازههای زمانی مختلف مقایسه کنید؛ بنابراین، خواهید توانست الگوریتمهایتان را بهینه و عملکردهای خود را نیز مقایسه کنید. در تصویر زیر، نمونه این نما نشان داده شده است:
5. CODE
در این نما، خواهید توانست کدهای بهکاررفته در تولید DAGG را مشاهده کنید:
تولید اولین DAG بهصورت گامبهگام
حالا بیایید اولین DAG را تولید کنیم. در این قسمت، بهصورت گامبهگام گردش کاری را ایجاد میکنیم که در آن ابتدا عبارت Getting Live Cricket Scores در ترمینال چاپ خواهد شد. سپس در مرحله بعدی با استفاده از API، امتیازها را بهصورت زنده در ترمینال چاپ خواهیم کرد.
گام اول: استفاده از کتابخانه cricket-cli
در اولین قدم، بیایید از API شروع کنیم. برای انجام این کار باید کتابخانه cricket-cli را با استفاده از کدهای زیر نصب کنیم:
sudo pip3 install cricket-cli
حالا دستورهای زیر را اجرا میکنین. بدینترتیب، امتیازهای مدنظر بهدست خواهد آمد:
cricket scores
خروجی کدهای بالا، مشابه تصویر زیر خواهد بود؛ البته بسته به سرعت اینترنت شما، این مدتزمان ممکن است متفاوت باشد:

گام دوم: Importکردن کتابخانهها
حالا همان گردش کار را با استفاده از Apache Airflow ایجاد خواهیم کرد. کدهایی که برای این منظور بهکار میگیریم، بهطورکامل با استفاده از سینتکسهای پایتون، اما برای ایجاد DAG خواهند بود. برای ادامه، بیایید با واردکردن کتابخانههای موردنیازمان شروع کنیم. در این قسمت، فقط به BashOperator نیاز داریم. دلیل آن هم این است که گردش کاری مدنظرمان فقط به اجرای عملیات Bash نیاز دارد. نحوه انجام این کار در تصویر زیر نشان داده شده است:
from datetime import timedelta # The DAG object; we'll need this to instantiate a DAG from airflow import DAG # Operators; we need this to operate! from airflow.operators.bash_operator import BashOperator from airflow.utils.dates import days_ago
گام سوم: تعریف آرگومانهای DAG
برای هریک از DAGها، باید یک آرگومان را Pass کنیم. درادامه به برخی از آرگومانهای مهمی اشاره کردهایم که میتوانیم Pass کنید:
Owner: نام Owner یا مالک میتواند ترکیبی از حروف و اعداد و نیز شامل Underline باشد؛ اما بههیچعنوان نباید در تعیین این نام، از Space استفاده کنیم.
Depends_on_past: اگر برای هربار اجرای گردش کار، دادهها به اجرای گذشتهشان بستگی دارند، مقدار این آرگومان را روی True قرار میدهیم؛ درغیراینصورت، مقدار False را برای آن انتخاب میکنیم. بهعبارت دیگر اگر این مقدار را بر روی True قرار دهیم، تنها در صورتیکه اجرایِ قبلی تسک موفقیتآمیز بوده باشد در این مرحله نیز اجرا خواهد شد.
Start_date: این آرگومان به تاریخ شروع گردش کار ما اشاره میکند.
Email: این گزینه همان آدرس ایمیل ماست. هنگامیکه هریک از Taskهای تعریفشده با شکست روبهرو شود، پیغامی به آدرس ایمیلی که در این آرگومان وارد شده است، ارسال خواهد شد.
Retry_delay: مدتزمانی که بعد از Failشدن هریک از تسکها برای شروع مجدد آن صرف میشود، در این آرگومان مشخص خواهد شد.
# You can override them on a per-task basis during operator initialization
default_args = {
'owner': 'lakshay',
'depends_on_past': False,
'start_date': days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'dag': dag,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function,
# 'on_success_callback': some_other_function,
# 'on_retry_callback': another_function,
# 'sla_miss_callback': yet_another_function,
# 'trigger_rule': 'all_success'
}
گام چهارم: تعریف DAGها
حالا میخواهیم DAG ایجاد کنیم. نام DAG را هم dag_id قرار میدهیم. دقت کنید که این نام باید منحصربهفرد باشد. برای این منظور، آرگومانهایی که در مرحله آخر تعریف کردیم، pass میکنیم و یک Description و Schedule_Interval نیز اضافه خواهیم کرد تا بعد از بازه زمانی مشخصشده، DAG اجرا شود. این کار با استفاده از کدهای زیر امکانپذیر است:
# define the DAG
dag = DAG(
'live_cricket_scores',
default_args=default_args,
description='First example to get Live Cricket Scores',
schedule_interval=timedelta(days=1),
)
گام پنجم: تعریف Taskها
در این پروژه، باید دو تسک را برای اجرای گردش کاری تعریف کنیم:
- Print: در این تسک، هدف این است که عبارت Getting Live Cricket Scores!!! را با استفاده از دستور echo چاپ کنیم.
- get_cricket_scores: در این تسک، چاپ نتایج زنده کریکت را با استفاده از کتابخانه نصبشده دنبال میکنیم.
برای تعریف هر تسک، باید اپراتور مناسبی نیز انتخاب کنیم. در این پروژه، چون هر دو تسک مبتنیبر ترمینال هستند، از BashOperator استفاده خواهیم کرد.
کاری که انجام میدهیم، بهطورخلاصه این است task_id را که شناسهای منحصربهفرد است، ارسال میکنیم و این شناسه را در نودهای Graph View مربوط به DAG خود خواهیم دید. دستور bash را که میخواهیم اجرا کنیم و درنهایت شیء DAG که میخواهیم این تسک را به آن لینک کنیم، ارسال میکنیم. درپایان نیز، با اضافهکردن عملگر >> بین تسکها، پایپلاین ایجاد میکنیم.
انجام این کار با استفاده از کدهای زیر امکانپذیر است:
# define the first task
t1 = BashOperator(
task_id='print',
bash_command='echo Getting Live Cricket Scores!!!',
dag=dag,
)
# define the second task
t2 = BashOperator(
task_id='get_cricket_scores',
bash_command='cricket scores',
dag=dag,
)
# task pipeline
t1 >> t2
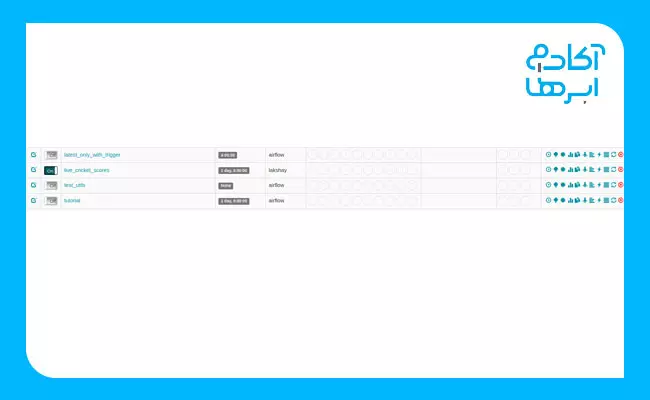
گام ششم: آپدیت DAGها در رابط کاربری وب
با آپدیتکردن رابط کاربری، DAG خود را در فهرست خواهیم دید. کلید سمت چپ هریک از DAGها را روشن و سپس DAG مدنظر را فعال میکنیم.
روی DAG مدنظر کلیک و Graph View را انتخاب میکنیم. در این صورت، با شکلی مشابه با تصویر زیر مواجه خواهیم شد. مشاهده میکنیم که هریک از مراحل در گردش کار در کادری جداگانه قرار گرفتهاند و پس از اتمام موفقیتآمیز، حاشیه آن به رنگ سبز تیره درخواهد آمد.

برای اینکه به جزئیات بیشتری دست پیدا کنیم، روی get_cricket scores کلیک میکنیم. در این صورت، چیزی شبیه به تصویر زیر برایمان به نمایش درخواهد آمد:
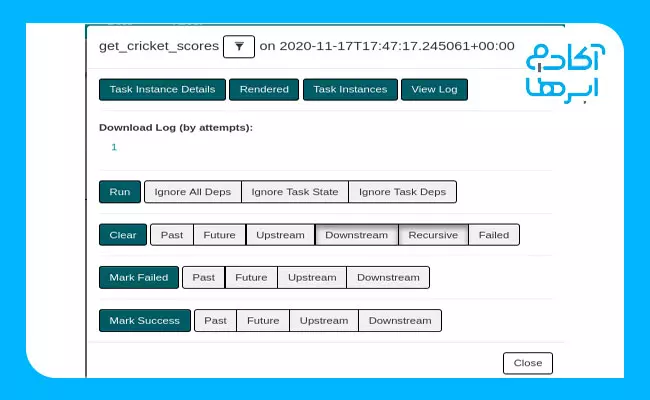
حالا روی View Log کلیک میکنیم تا بتوانیم خروجی کدهای خود را ببینیم. نمونهلاگهای گزارششده در تصویر زیر نشان داده شده است:

بدینترتیب، اولین DAG خود را در Apache Airflow ایجاد کردهایم.
جمعبندی
در این مقاله، تاریخچه Apache Airflow و مزیتهای استفاده از این ابزار و مفاهیم اولیهای را بیان کردیم که برای استفاده از آن باید بهیاد داشته باشید. استفاده از Apache Airflow در مهندسی داده یکی از ابزارهای بسیار کارآمد و معروف است که باعث میشود پایپلاینهای خود را با استفاده از کدهای پایتون و بهصورت کاملاً توسعهپذیر تعریف کنید. Airflow میتواند با ابزارهای مختلف دیگری ترکیب شود و به اکوسیستم داده شما نظم و انسجام بدهد.
سؤالات متداول
۱. ایرفلو چیست؟
آپاچی ایرفلو یا بهطورخلاصه ایرفلو، یکی از ابزارهای بسیار کارآمد در مهندسی داده است. با استفاده از این ابزار، جریان کاری را بهصورت تخصصی و حرفهای میتوانید مدیریت کنید.
۲. آپاچی ایرفلو چه کاربردی دارد؟
کاربرد این ابزار زمانی مشخص خواهد شد که بخواهید فرایند تکراری مبتنیبر داده را بهصورت اتوماسیون انجام دهید. بهعنوان مثال، فرض کنید یکی از گردشهای کاری شما جمعآوری داده بهصورت مرتب از چندین پایگاهداده باشد. در این مواقع، آپاچی ایرفلو بهکمک شما خواهد آمد.
۳. مخاطبان یادگیری آپاچی ایرفلو چه کسانی هستند؟
تمامی افرادی که با داده سروکار دارند، مخاطبان این نرمافزار هستند؛ بنابراین، چه متخصص داده باشید و چه بهتازگی وارد علم مهندسی داده شده باشید، استفاده از ایرفلو برایتان بسیار کاربردی خواهد بود.
۴. ایرفلو چه ویژگیهایی دارد؟
استفاده آسان، UI کاربرپسند، قدرت چشمگیر و متنبازبودن، ازجمله مزایای این ابزار قدرتمند بهشمار میآیند.






دیدگاهتان را بنویسید